
今天,我们发布并开源首个混合线性架构的万亿参数思考模型 Ring-2.5-1T。
作为迈向通用智能体时代的关键步骤,我们将混合线性注意力架构在预训练和强化学习上均进行了大规模扩展,一方面利用高效的 1:7 MLA + Lightning Linear Attention 架构来提升模型的思考效率和探索空间,另一方面通过扩展强化学习和智能体环境规模来提升模型的思考深度和长程执行能力。
相比此前发布的 Ring-1T,Ring-2.5-1T 在生成效率、思考深度、长程执行上均有大幅提升:
高效生成:得益于高比例的线性注意力机制,在超过 32K 生成长度下,访存规模降低 10 倍以上,生成吞吐提升 3 倍以上,尤其适合深度思考和长程执行的任务。
深度思考:在 RLVR 基础上引入 dense reward 来反馈思考过程的严谨性,使得 Ring-2.5-1T 同时实现 IMO 2025 和 CMO 2025 的金牌水平(自测)。
长程执行:通过大规模 fully-async agentic RL 训练,显著提升针对复杂任务的长程自主执行能力,使得 Ring-2.5-1T 可以轻松适配 Claude Code 等智能体编程框架和 OpenClaw 个人 AI 助理。

深度思考与长程执行
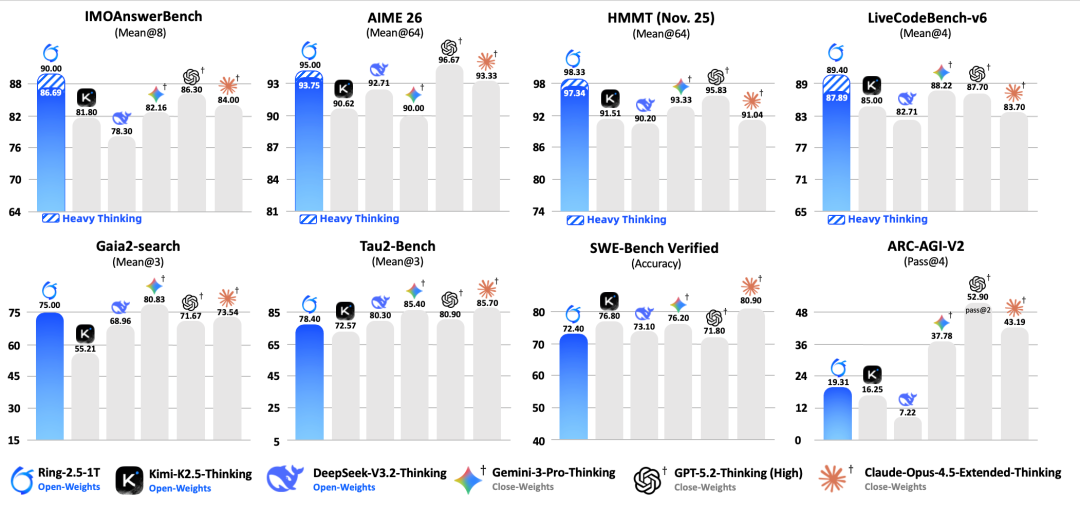
为评估 Ring-2.5-1T 的深度思考和长程执行能力,我们选取了具有代表性的开源思考模型(DeepSeek-v3.2-Thinking、Kimi-K2.5-Thinking)和闭源API(GPT-5.2-thinking-high、Gemini-3.0-Pro-preview-thinking-high、Claude-Opus-4.5-Extended-Thinking)作为参考。 Ring-2.5-1T 在数学、代码、逻辑等高难推理任务(IMOAnswerBench、AIME 26、HMMT 25、LiveCodeBench、ARC-AGI-V2)和智能体搜索、软件工程、工具调用等长程任务执行(Gaia2-search、Tau2-bench、SWE-Bench Verified)上均达到了开源领先水平。
我们还额外测试了深度思考模式(heavy thinking mode),通过在推理过程中扩展并行思考与总结,实现测试时扩展,从而有效提升推理的深度与广度。
在 IMO 2025(满分 42 分)中,Ring-2.5-1T 获得 35 分,达到金牌水平;在 CMO 2025(满分 126 分)中取得 105 分,显著高于金牌线(78 分)及国家集训队入选线(87 分)。对比 Ring-2.5-1T 与 Ring-1T 的答题结果可以发现,前者在推理逻辑严谨性、高阶数学证明技巧使用以及答案表述完整性方面均有明显提升。我们现已公开 Ring-2.5-1T 在 IMO 2025 与 CMO 2025 中的详细解答,完整内容可通过以下链接查看:https://github.com/inclusionAI/Ring-V2.5/tree/main/examples
此外,在挑战性的智能体搜索 GAIA2-search 任务中,Ring-2.5-1T 达到开源 SOTA 水平。GAIA2 环境强调跨应用工具协作与复杂任务执行能力,Ring-2.5-1T 在规划生成与多步工具调用上的效率与准确性均表现突出。

万亿规模的混合线性注意力架构
在通用智能体时代,深度思考(deep thinking)与长程执行(long-horizon agent)正成为语言基座的基本工作范式。这一转变对基座模型在长程推理解码效率上的架构能力提出了极高要求。作为迈向智能体模型(agentic model)架构的关键一步,Ling 2.5 架构在 Ling 2.0 架构基础上引入了混合线性注意力架构。通过增量训练方式,将 Ling 2.0 架构的 GQA 升级为 1:7 的 MLA + Lightning Linear结构。具体而言,我们基于此前发布的 Ring-flash-linear-2.0 技术路线,将部分 GQA 层改造为 Lightning Linear Attention,以显著提升长程推理场景下的吞吐能力。为进一步压缩 KV Cache,我们将其余 GQA 层近似转换为 MLA ,并对其中的 QK Norm 、Partial RoPE 等特性进行了针对性适配,以增强 Ling 2.5 架构在混合注意力架构下的表达能力。
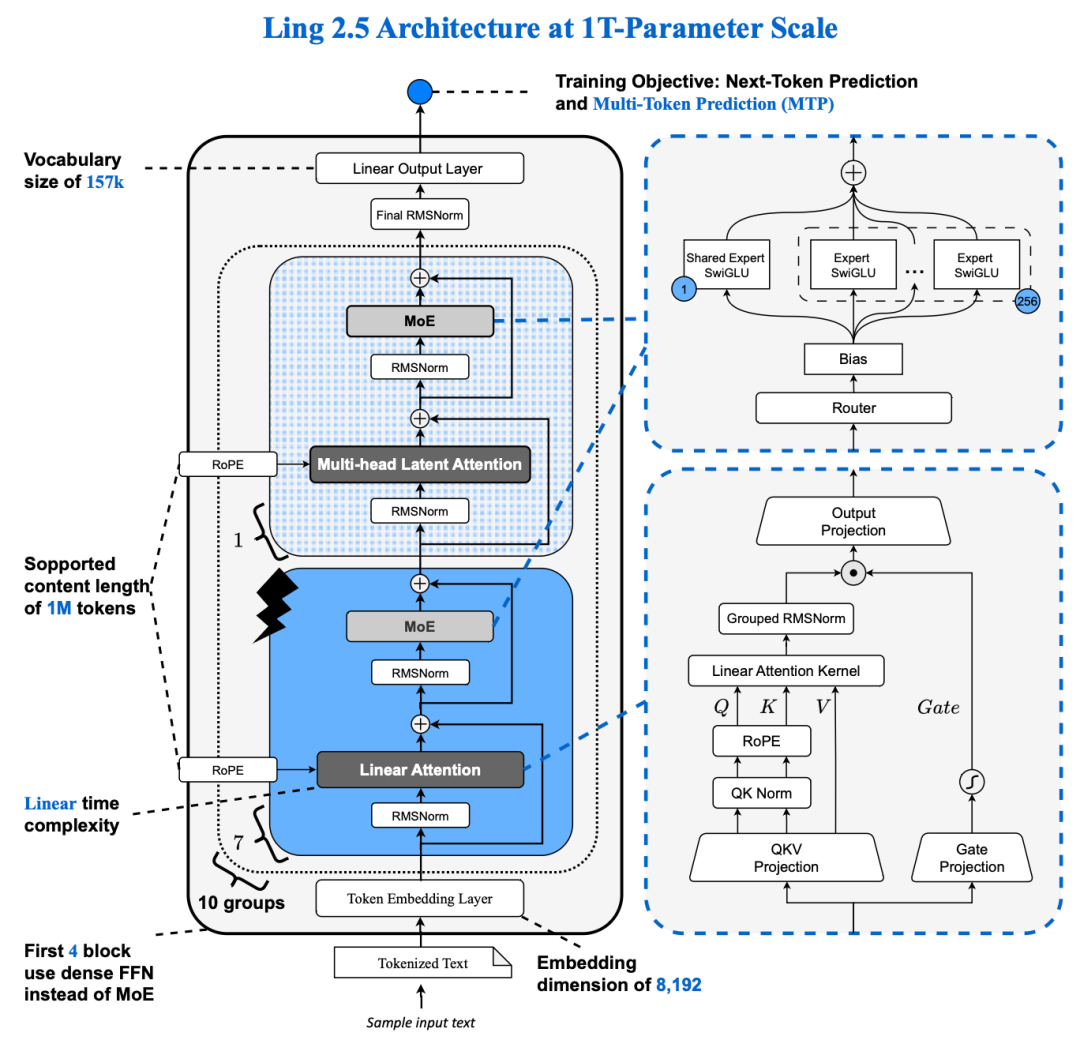
1T规模下的 Ling 2.5架构
改造后,Ring-2.5-1T 的激活参数量从 51B 提升至 63B。但在混合线性注意力架构的支持下,其推理效率相比 Ling 2.0 仍实现了大幅提升。即便与激活参数仅为 32B 的 KIMI K2 架构相比,1T 规模下的 Ling 2.5 架构在长程推理场景下的吞吐依然具有显著优势;且生成长度越长,吞吐优势越明显。
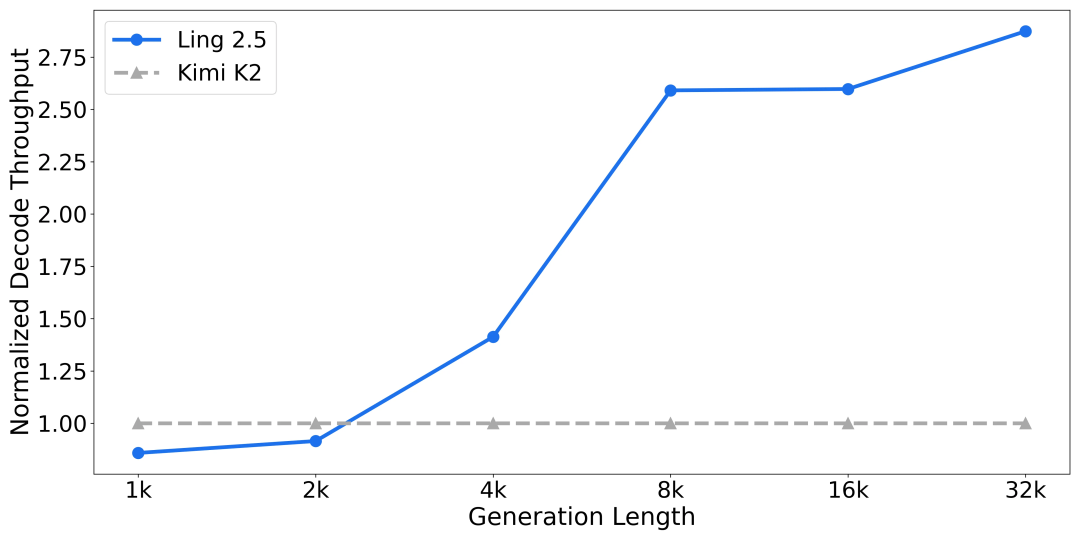
单机 8 卡 H20-3e ,batch size = 64 ,
不同生成长度下的解码吞吐(decode throughput)对比
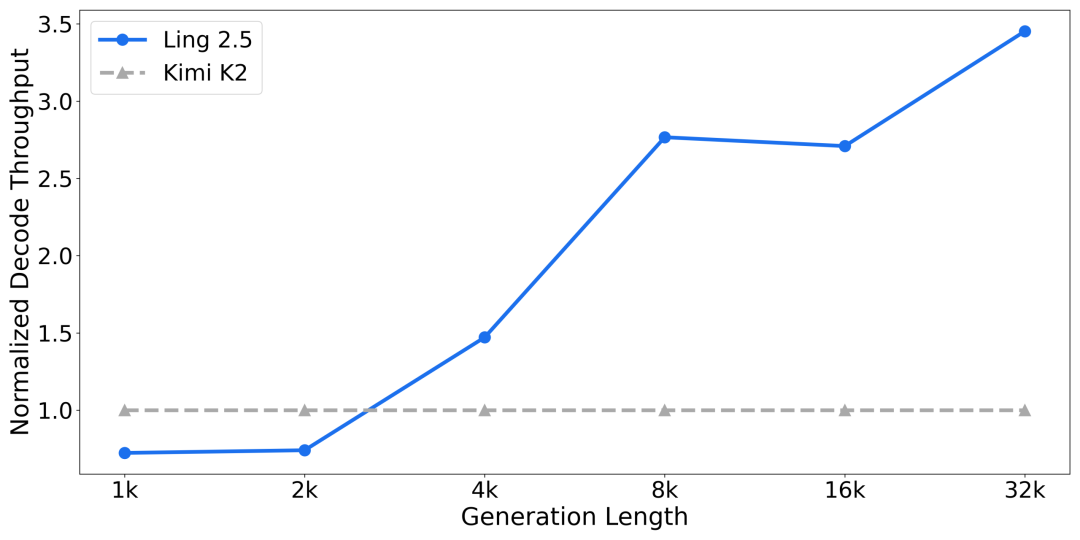
单机 8 卡 H200 ,batch size = 64 ,
不同生成长度下的解码吞吐(decode throughput)对比

手搓案例
我们将 Ring-2.5-1T 接入到 Claude Code 中,为测试其长程软件开发能力,我们通过如下的 prompt 要求其自动开发一个微型版操作系统(TinyOS)。
1. 系统启动流程:
- 使用 GRUB 作为引导加载程序,遵循 Multiboot 标准
- 编写 boot.asm 汇编文件设置基本的 CPU 模式(32 位保护模式)
- 从汇编跳转到 main.c 的 kernel_main 函数
2. 核心功能实现:
- 屏幕输出:实现简单的字符显示功能(如清屏、打印字符串)
- 中断处理:设置基本的 GDT 和 IDT,处理键盘输入中断
- 内存管理:实现最基本的内存分页初始化
- 键盘支持:能够接收键盘输入并回显到屏幕
3. 代码结构:
- 提供完整的 linker.ld 链接脚本
- 提供 Makefile 用于编译和生成 ISO 镜像
- 每个关键函数都要有清晰的注释说明
4. 代码要求:
- 确保代码简洁、模块化,避免不必要的复杂性
- 优先实现可工作的最小功能集
- 为后续扩展预留接口
请先输出完整的代码文件列表和简要说明,然后提供每个文件的完整代码。
生成的所有代码必须能直接编译运行,并给出具体的编译和测试方法。
你需要保证可以使用 qemu 来实际运行这个操作系统。
Ring-2.5-1T 在 Claude Code 中运行了 2 小时 8 分钟,最终完成了上述任务,详细记录如下视频:
我们尝试继续让 Ring-2.5-1T 丰富 TinyOS 的功能,输入如下 prompt:
好的,现在你继续开发,实现好 bash 的功能,使得使用 qemu 可以登录到一个 bash 命令界面,以执行一些简单的命令,比如 ls、pwd、cat 等。
最终开发的 TinyOS 如下视频所示:
我们也将 Ring-2.5-1T 接入到个人 AI 助理 OpenClaw,帮助阅读 AI infra 文献,并用 JAVA 代码展示技术逻辑。

局限性与未来计划
这一版本模型在 token efficiency 与指令遵循方面仍存在不足,在面向更真实、更复杂任务的长程执行与实际交付能力上,也仍有较大的优化空间。我们将在后续版本中持续改进上述能力,并非常期待来自社区的使用反馈与建议。目前,Ring-2.5-1T 的训练仍在持续推进中。完整技术报告将在下一版本发布后正式公开。
此外,需要说明的是,上述 GAIA2 榜单评测采用的是社区广泛使用的 OpenAI function call 格式,而非原始的 ReAct 格式。相关评测配置与方案将提交至 GAIA2 的 GitHub 仓库,供社区进行更广泛、可复现的对比与评测。
欢迎大家访问我们的开源仓库和体验页面进行下载使用
🤗 Hugging Face:
https://huggingface.co/inclusionAI/Ring-2.5-1T
🤖 ModelScope:
https://modelscope.cn/models/inclusionAI/Ring-2.5-1T
Ling Studio(https://ling.tbox.cn/chat) 与 ZenMux(https://zenmux.ai/) 的 Ring-2.5-1T Chat 体验页和 API 服务将在近期上线。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢