
阿里巴巴未来生活实验室与智能引擎、数据技术团队正式发布智能体模型ROME-V0.1(ROME is Obviously an Agentic ModEl)。
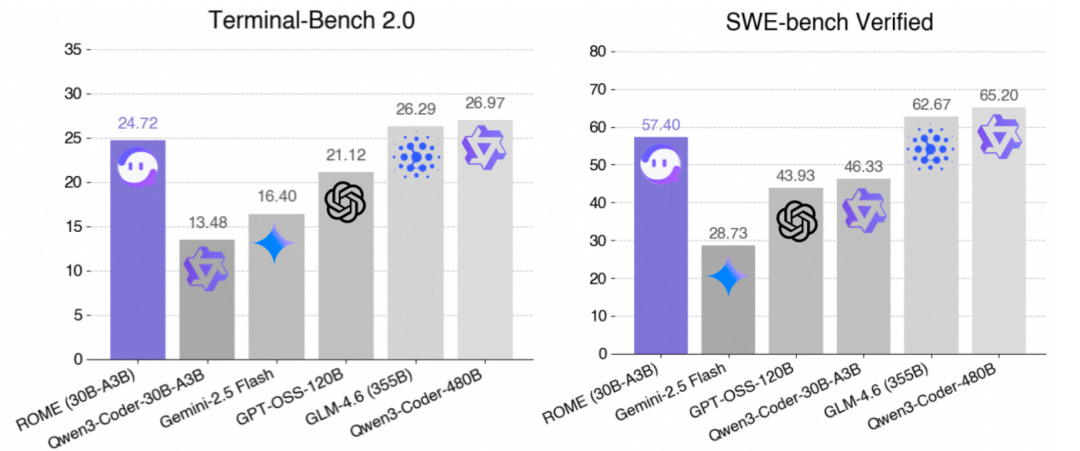
在多项主流 Agent 基准测试中,IFLow-CLI + ROME-V0.1在同规模开源模型中取得了领先结果,并在部分榜单上接近 100B+ 参数规模模型——例如,在 Terminal-Bench 2.0 上达到 24.72% 的成功率,在 SWE-bench Verified 上取得 57.40% 的任务完成率。
ROME-V0.1 是面向真实执行场景训练的智能体模型,其并非针对某些单一评测的优化,而是建立在大规模真实环境交互、端到端执行闭环训练以及面向长链任务的强化学习范式之上。得益于完善的训练系统基建--ALE(Agentic Learning Ecosystem),ROME-V0.1 在 超过百万数量级别的可验证交互轨迹上完成训练。
需要强调的是,ROME-V0.1 并不是一次“拼性能”的大规模模型尝试,而是一项围绕 Agent 模型应该如何被训练出来的系统性探索。
下文将详细介绍,这一套 Agent 训练体系是如何一步步构建,并最终支撑起 ROME 的诞生。

2025年 8 月, iFlow CLI正式发布。这是一个面向真实工程场景的 Agent 产品, 基于开源模型,我们不断改进框架,使其更贴合开发中的实际需求, 迅速获得一批真实用户, 同时也在用户的反馈中发现:
显然,这不是“模型还不够大”的问题,而是更多地暴露出一个现实问题:现有训练体系对智能体模型在真实任务环境中的执行与反馈的建模仍然不足。
对一个合格的Agent 来说,真正的难点是如何具备在真实的环境中自主收集信息、执行交互,最终完成任务的能力,而不只是“纸上谈兵”。而要解决这个难点,就要构建真实的训练场,让模型在真实环境中交互和学习,一步一步地去试错并修正,最终实现能力上的进化。可惜的是,这部分内容往往很少被人关注或提及,且相关工作在开源社区里几乎是一片空白。
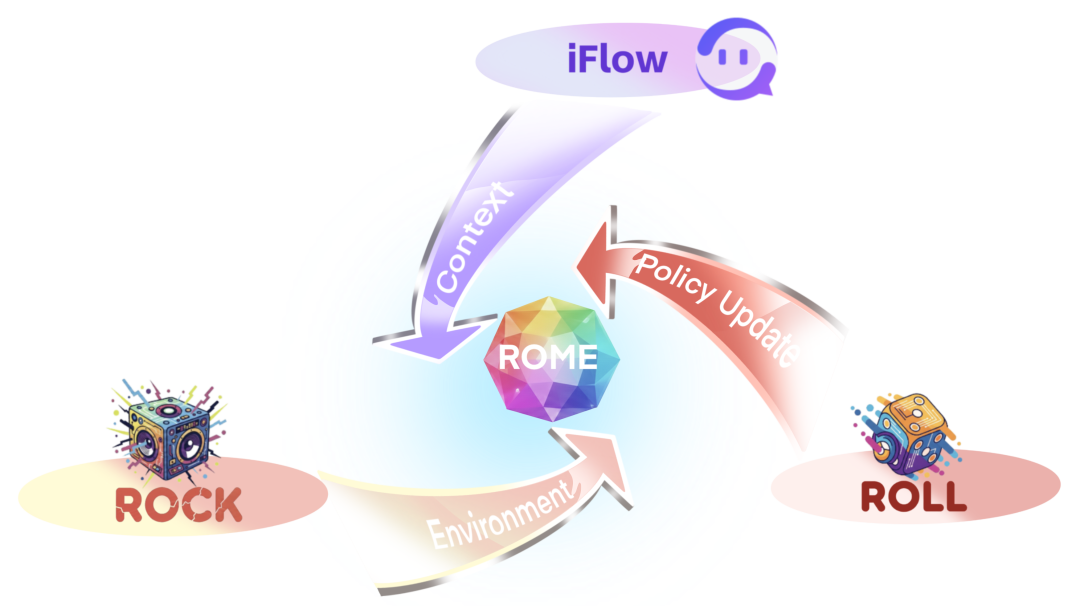
为了打破这个困局,阿里巴巴未来生活实验室(Future Living Lab)与智能引擎、数据技术团队将丰富的内部实践经验沉淀为开源基础设施,隆重推出了智能体学习生态系统ALE (Agentic Learning Ecosystem)。该系统旨在解决 Agent 训练里最现实的几个问题:
1. 训练数据通常为脱离环境的静态文本,缺少规模化的高质量实战数据。
“纸上得来终觉浅”,如果只是一味在静态的交互轨迹上进行学习,模型的泛化能力难以得到保障。只有让模型与环境动态进行交互,在不断的试错中学习,才能使之真正掌握遇到真实问题时实时分析和解决的能力。
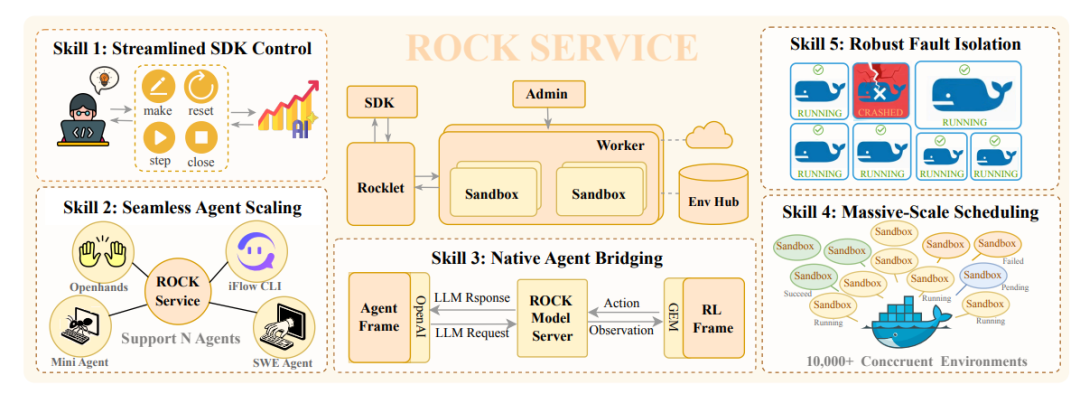
为此,团队用自主研发的沙盒管理器 ROCK(Reinforcement Open Construction Kit)构建了万级别并发的沙盒训练场,以 GitHub 真实项目为基础,通过实时交互为模型训练提供超过 100 万条具备环境反馈的交互轨迹。ROCK 的存在确保了模型在训练阶段接触到的每一个操作,都有真实环境的运行结果作为反馈,从而支撑其解决现实问题的能力。
2. 复杂工程任务链路极长,长尾rollout导致训练效率低下。
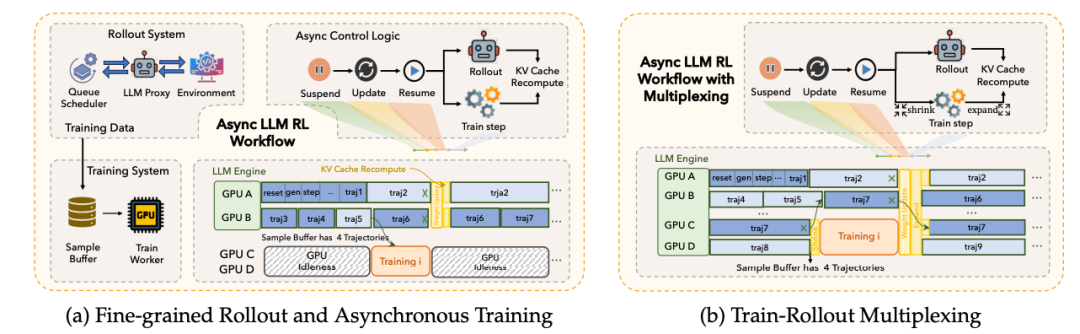
强化学习的Rollout效率优化是一个老生常谈的问题,而在Agent相关的复杂任务中,由于不同任务的难度、复杂度差异较大,环境交互与样本生成的长尾现象也更加严重。为了等待某些任务轨迹完成采集,往往会拖慢整个链路的节奏,极度影响训练效率。
为此,团队用自主研发的大模型强化学习训练框架 ROLL (Reinforcement Learning Optimization for Large-Scale Learning)实现了极致的分布式并行化与异步加速,大大提升了训练效率。ROLL 的异步训练pipeline极大地缩短了轨迹采样和策略优化的耗时,支持模型在海量任务中同步进行试错迭代,让模型能在单位时间内完成更高频次的闭环训练,从而在海量训练任务中练就稳健的执行能力。
3. 缺乏标准化的上下文衔接与工具调用协议,难以实现端到端的闭环优化。
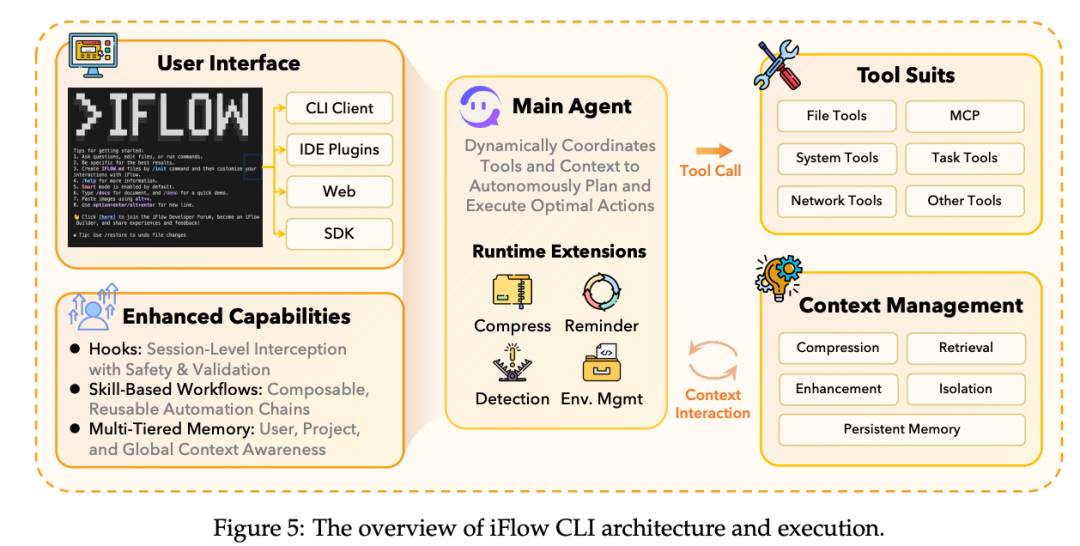
想要让模型能够顺利地在训练中与环境完成高效交互,往往需要标准化的上下文衔接与工具调用协议来保障模型推理状态与环境执行反馈之间的顺畅链接。一旦这个环节出现问题,就会导致长链条任务中的交互逻辑极易断裂且难以实现端到端的闭环优化。
为此,团队通过自主研发的智能体框架 iFlow CLI 实现了标准化的上下文管理与灵活开放的配置设定,消除了训练与实战的隔阂。这样以来,Agent 模型能够在复杂任务的工作流中时刻保持与环境实时顺畅的交互,从而保障了整个系统链路的稳定性与持久训练迭代的可能性。
ROME 并非针对某些评测基准特定优化的模型,而是基于 ALE 基础设施,自然而然的诞生。在千万数量级别的模拟环境里不断训练、收集反馈、持续优化。它的能力,是从一次次真实交互中进化而来。
在技术报告中,团队系统性地披露了 ROME 背后的关键技术细节和创新,核心目标只有一个:
以下是部分关键技术:
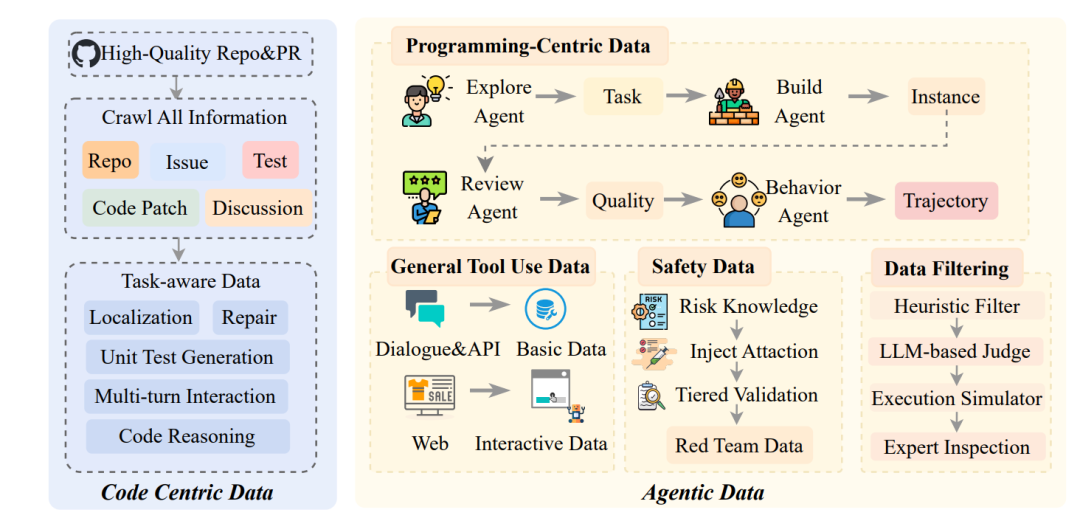
传统 LLM 的训练数据主要来源于静态文本语料,这类数据缺乏可执行的环境约束与明确的反馈信号,使模型难以感知自身行为在真实系统中的后果。
同时主流的LLM数据合成范式更多是doc-centric(围绕文档或是代码片段)或是query-centric(围绕问题)来组织扩充语料,缺乏对真实执行环境、工具链差异以及运行状态的建模能力。模型容易学到“看起来合理”的文本模式,而“在真实条件下不能跑通”的行为策略
因此ROME主要采用environment-centric的数据构建范式。团队首先大规模构建和扩充可复现的执行环境与可运行的任务实例(instances),再在这些实例之上系统性生成多轮交互轨迹, 每个instance包括:任务描述、Docker环境、初始化脚本、测试文件与golden solution等。
在这一路径下,所有生成的轨迹都是经过运行与测试验证。同时不同环境与工具之间的差异也都会体现在不同的轨迹之中,使模型从一开始就被约束在“可执行、可验证”的学习目标上。
依托 ROCK 提供的高并发沙盒调度与隔离能力,该数据构建机制以流水线化方式持续运行。最终形成了超过百万级、具备完整环境反馈的高质量交互轨迹,为后续的 Agent 训练提供了稳定而可验证的基础。
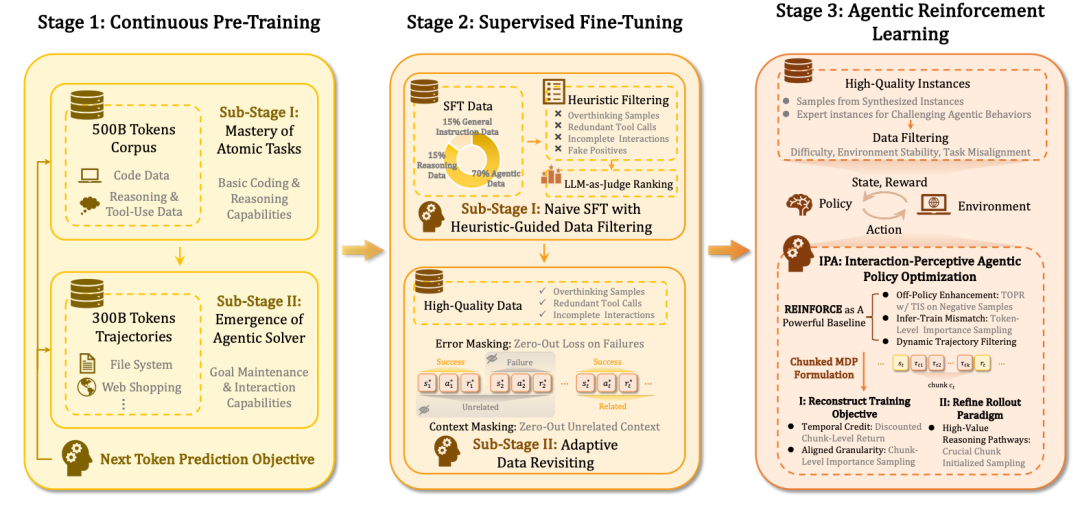
在训练链路上,ROME 并未简单沿用“预训练—微调—强化学习”的通用范式,而是围绕 Agent 能力的逐级形成过程,设计了一套课程化的三阶段训练体系。
该体系以能力解耦为前提, 逐步引导模型从学习基础agentic行为到能够具备解决高难任务的智能体
1. 阶段一:CPT(持续预训练)—— 构建基础 Agentic 能力
在 CPT 阶段,训练目标并非直接优化任务成功率,而是为模型系统性注入基础 Agent 能力,包括:
代码理解与修改代码理解与修改
任务分解与阶段性规划任务分解与阶段性规划
工具使用与多步推理工具使用与多步推理
对环境状态变化的感知能力对环境状态变化的感知能力
同时数据筛选并不以结果正确性为唯一标准,而是主要关注行为模式的覆盖率, 通过该阶段引入多样化的交互轨迹为后续的策略优化提供充分的可激发空间。
2. 阶段二:SFT(监督微调)—— 面向交互稳定性的对齐训练
SFT阶段的核心目标还将后续强化学习锚定在可靠、可执行的策略区域内,避免较高频率出现低质量或不可执行行为
为此,ROME 采用了 两阶段 SFT 训练策略:
第一阶段:基于启发式规则进行数据过滤的轻量 SFT,确保模型具备正确的行为模式
第二阶段:引入自适应样本筛选机制,对具有高学习价值的交互轨迹进行重点增强
在此过程中,团队也对传统 SFT 目标函数进行了重新设计。在长链交互中,工具调用错误或执行失败极为常见,若对所有 token 一视同仁地反向传播梯度,反而会无意中强化错误行为。
为此,ROME 引入了错误掩码训练机制:
基于工具执行反馈,将不可执行或失败行为对应的梯度置零
同时,在多子 Agent 场景中,系统会识别特定任务的决策边界,仅保留与当前子任务直接相关的上下文回合。
通过基于模式的启发式识别,对冗余、高度相似或已被剪枝的历史回合屏蔽损失梯度,使学习信号集中于真正具有因果影响的交互过程,从而显著提升样本效率。
3. 阶段三:IPA 强化学习—— 从对齐到策略进化
在完成基础对齐后,ROME 进入基于 IPA(Interaction-Perceptive Agentic Policy Optimization)的强化学习阶段。该阶段的核心目标,是在真实环境约束下进一步提升模型在长链任务中的决策质量与执行稳定性。
针对在长时程的agent任务中,传统的奖励机制往往面临信用分配困难、奖励信号稀疏的问题,团队提出了 IPA (Interaction-Perceptive Agentic Policy Optimization) 算法。该研究的核心在于将优化目标从传统的“Token 粒度”提升到“语义交互块 (Interaction Chunk)”级别,极大提升了强化学习在复杂交互场景下的训练稳定性。
🌟Chunked Markov Decision Process(交互块级别的马尔可夫决策过程)
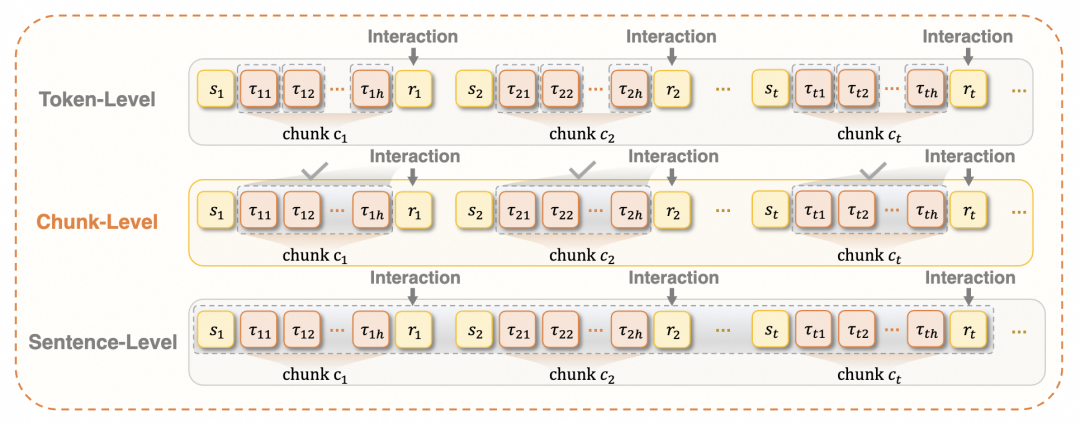
为了能更好地引出后续在交互块级别的算法优化,首先在交互块层面重新建模了马尔可夫决策过程(Markov Decision Process,MDP)。然后在Token级别MDP的基础上,将一个完整的token序列划分为一个一个的交互块,每个交互块覆盖了连续两次环境交互之间的过程,构成一个完整的决策单元。以工具调用为例,一个交互块包含了“分析推理->工具调用->触发执行”的完整过程。这种建模方式可以把轨迹中共同影响某一次环境交互的token很好地聚合成一个整体,使得每个优化目标(交互块)都可以与同一次环境交互对应,有利于实现更准确的信度分配。
1. Chunk-Level Discounted Return(交互块级别的折扣回报)
在传统的强化学习算法中,折扣奖励扮演着相当重要的角色。如果没有时间折扣奖励,就将无法衡量行为和奖励之间在时间距离上的因素,进而导致长尾轨迹中早期行为的价值估计存在较高的方差,最终影响训练的稳定性。而在大模型的强化学习训练中,传统基于token的优化方法天然的难以引入有意义的折扣奖励。这是因为一次完整的轨迹中往往包含了成千上万个token。折扣因子(<1)会在这些token上以指数级速度衰减并无限接近0。这会导致轨迹中相当多的token被过度降低奖励权重,使之难以获得有效的梯度更新,进而导致训练相当低效。
随着将优化目标从token层级聚合到交互块层级,奖励折扣的时间步可以与实际的每一次环境交互完美对齐,折扣因子的衰减次数被大大降低,从而避免了早期交互被过度降权。自然地,团队在交互块级别重新引入了折扣回报,来缓解长交互轨迹信度分配中的偏差-方差平衡问题。通过合理地对奖励施加交互块级别的时间步衰减惩罚,可以很好地避免早期尝试时的无效操作(例如无效的工具调用)被过度奖励,促使模型更高效地学习高影响力的交互步骤,进而提高样本的利用效率和训练的稳定性。
2. Chunk-Level Importance Sampling(交互块级别的重要性采样)
更进一步地,团队提出了交互块级别的重要性采样。类似GSPO在序列级别的重要性采样计算方式,在每个交互块内部计算所有token上的训练分布的概率和采样分布的概率的比值,用这些概率比值的几何平均值来衡量交互块级别的采样概率差异,这样可以减弱异常token的影响并避免极端比值的出现。进一步结合交互块级别的奖励分配,我们可以用交互块级别的重要性采样来调整优化目标从而弥补采样分布和训练分布之间的偏差导致的训练不稳定。
3. Chunk-Level Initialized Resampling(交互块级别的初始化重采样)
强化学习的有效性和稳定性除了算法本身的优化外,还取决于采样数据的质量和奖励信号的丰富性。在一些较为复杂的多轮交互任务中,如果模型无法在每一个关键点稳定地做出正确决策,任务成功率将以指数的速度快速降低,最终导致这些任务上的正信号极其稀疏。一方面,正向信号的缺失使得训练缺乏引导,降低了收敛速度和探索效率,使得模型难以逃离次优区域;另一方面,过多的负向奖励将会持续降低轨迹上的token概率并分配到其他token上,提高了崩溃的风险。
为了解决这一问题,IPA使用了交互块级别的初始化重采样方法(Chunk-Level Initialized Resampling)。该方法利用成功的参考轨迹(来自模型本身或外部专家模型生成)中的交互块作为锚点,通过使用这些交互块“预填充”轨迹的前半部分并执行交互,使环境被初始化到这些成功轨迹的中间状态。接着,模型就可以从中间状态“重采样”后续的交互块并继续与环境交互,补完整条轨迹并获取最终的奖励。这种重采样方式可以让模型“站在巨人的肩膀上”:利用成功轨迹锚定部分交互,降低整体任务难度的同时,让模型先学习如何完成后面的步骤,再修改初始化点,最终逐步学会解决整个任务。
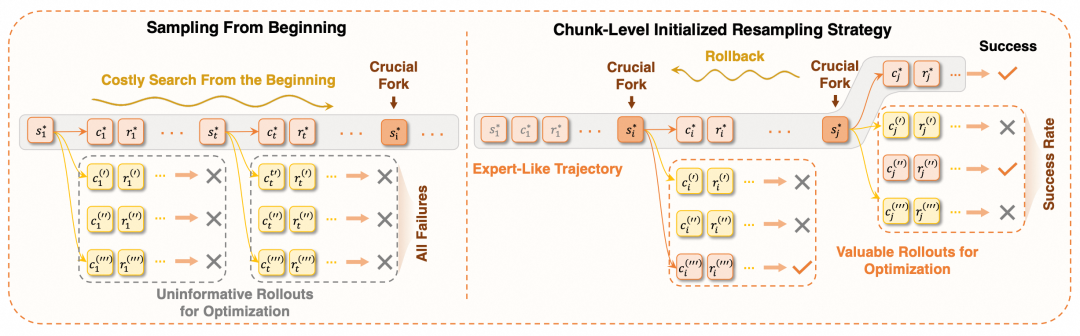
为了更好地决定在参考轨迹上具体的初始化位置,IPA首先提出了一种序列回退(Sequential Rollback)的方式。该方式选择从参考轨迹的最后一个交互块的位置开始进行初始化,并记录该位置重采样轨迹的成功率,然后“回退”初始化点到上一个交互块执行前的状态。当模型的重采样成功率在某次回退后骤降,我们就定义这次回退越过的的参考交互块为一个“关键交互”--即可以显著提升重采样成功率但模型尚未熟练掌握的交互决策。此时模型停止回退,从该交互块执行前的状态开始多次重采样后续交互轨迹并学习,直到熟练掌握后再继续“Rollback”。此外,考虑到数据本身的特性和一些极端案例,IPA在序列回退的基础上又提出了并行初始化(Parallelized Initialization)方法,使模型可以同时从参考轨迹的多个初始化点开始重采样,并且引入了对参考交互块的模仿学习,大大加速了训练的效率。
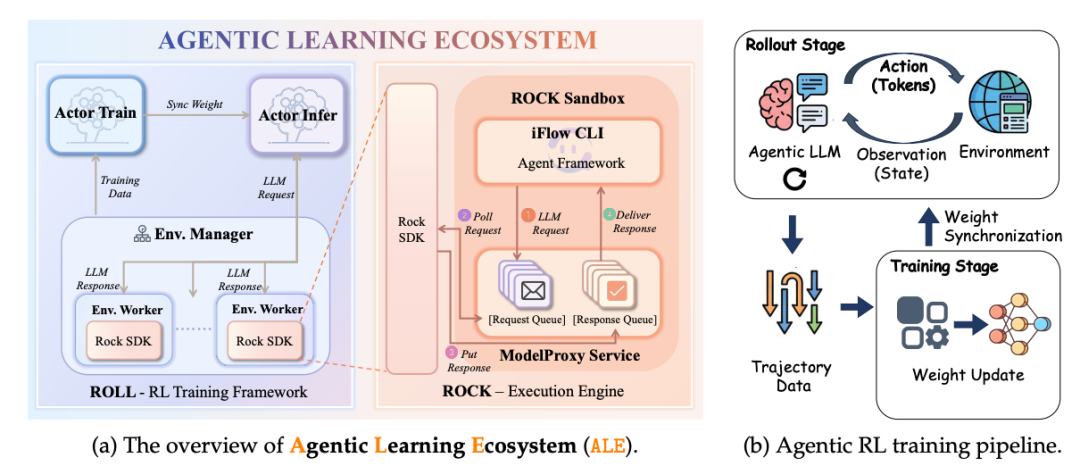
在许多 Agent 训练链路中,训练时使用的上下文组织方式,与实际的agent框架存在显著差异,导致模型能力在生产环境中出现退化。在许多 Agent 训练链路中,训练时使用的上下文组织方式,与实际的agent框架存在显著差异,导致模型能力在生产环境中出现退化。
ROME通过Agent-Native Training从根本上解决了Agent训练与真实使用场景之间的差异问题
训练阶段直接复用iflow CLI完整的执行逻辑
在训练过程中,ROLL不使用人为重写的 prompt 拼接或简化的 Agent scaffold,而是直接调用 iFlow CLI 运行真实 Agent。
这意味着模型输入包含了iFlow CLI动态生成的上下文:包括长上下文压缩,可调用工具的更新,各种系统提示与中间状态管理,使RL训练阶段看到的输入分布与线上使用时保持一致。
通过ModelProxy Service实现“无侵入式”Agent 训练
为避免在训练框架中重复实现 Agent 逻辑,ROCK 在沙盒内引入了ModelProxy Service。Agent 在沙盒内仍然按照原有方式调用模型接口,而这些请求会被 ModelProxyService 异步转发至 ROLL 拉起的推理服务,而后再将推理结果再回传给 Agent。
ROLL 无需感知 Agent 的 prompt 结构或上下文管理细节,即可对真实 Agent 行为进行训练。
训练、蒸馏与评测复用同一执行链路
由于训练阶段直接运行真实 Agent,数据合成、强化学习、蒸馏与评测均可复用同一套执行与环境交互逻辑。
这一设计显著降低了 Agentic RL 的工程复杂度,同时确保不同阶段之间不存在行为偏移,也为后续消融实验与 Agent 框架切换(如 iFlow CLI、SweAgent、OpenHands)提供了统一接口。
Agent-Native 设计保证了模型在 训练、评测与真实部署 三个阶段中的行为高度一致, 总结来说“ROME不是在一个模拟agent中训练,而是在真实环境直接训练agent本身”。
这套端到端的完整解决方案,覆盖从环境构建、并行采样、策略优化到生产部署的全链路。
在这一体系下,ROME-V0.1 并不是一次“追求极限性能”的规模尝试,而是以环境与执行为中心的 Agent 训练范式的一次完整落地验证。因此,选择首先发布 30B MoE 这一规模:在保证足够能力的同时,更强调可训练性、可部署性与可复现性,使完整的 Agent 训练闭环能够以极高的效率和性价比稳定运行。
同时希望降低 Agentic LLM 的使用与迭代门槛,让更多让个人开发者和团队在本地或私有环境中构建属于自己的 Agent CLI。欢迎大家在 iFlow CLI 论坛中分享硬核 Case 和创新Agent 设计,共同推动 Agent 能力在真实环境中的演进。
团队将沿着 ALE 已经跑通的训练链路,系统性地扩展环境规模与任务复杂度,并同步推进模型迭代。
ROME,只是开始。
想了解 ROME 背后更多的细节?点击下方【阅读原文】,获取论文全文。
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢